Por qué ChatGPT es más caro en español que en inglés
El sistema que establece el coste de la información creada por la IA generativa supone una gran diferencia al usarla ente distintos idiomas

La investigación, realizada por Aleksandar Petrov, Emanuele La Malfa, Philip H.S. Torr y Adel Bibi muestra como, por ejemplo, el chino simplificado es el doble de caro que el inglés y la lengua Shan (Birmania), en el otro extremo, 15 veces más.

Una diferencia en la duración de la tokenización que es un problema porque la API de OpenAI se factura en unidades de 1000 tokens . Por lo tanto, si tiene hasta 15 veces más tokens en un texto comparable, el costo de procesamiento será 15 veces mayor.
Los tokens son la unidad de medición que representa el coste computacional de acceder a un modelo de lenguaje a través de una API, que es una pieza de código que permite a diferentes aplicaciones comunicarse entre sí para compartir información y funcionalidades.
De hecho, los modelos a nivel de caracteres y a nivel de bytes también exhiben más de 4 veces la diferencia en la longitud de codificación para algunos pares de idiomas.
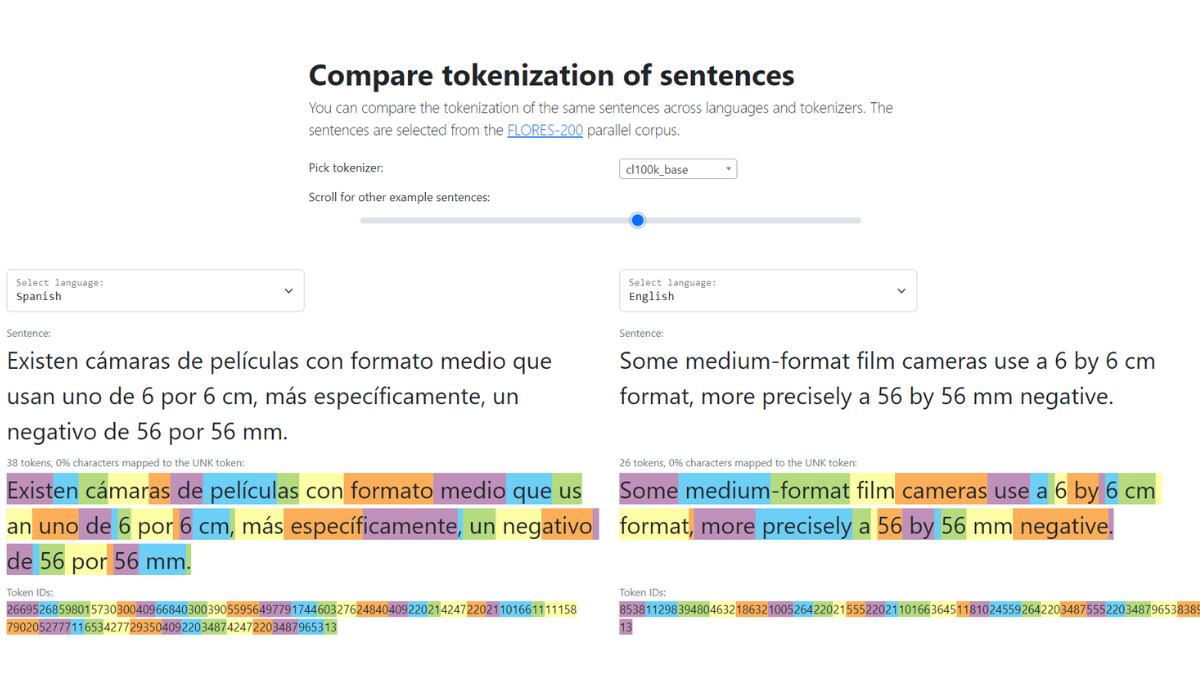
OpenAI cuenta con un tokenizador del modelo de lenguaje GPT-3 en el que puede comprobarse las diferencias entre el inglés y otros idiomas.
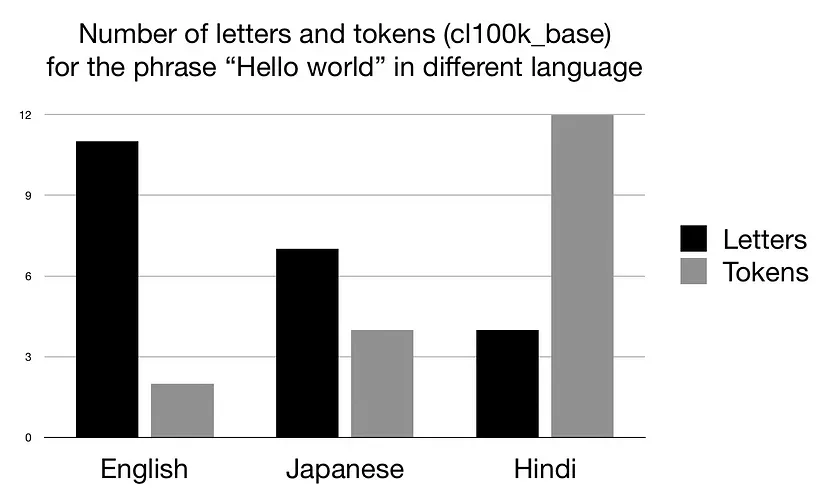
Una expresión como “tu afecto” son solo 2 tokens en inglés, pero 8 en chino simplificado. Esto sucede a pesar de que la expresión en chino necesita menos caracteres que en inglés.
En español también son menos caracteres que en inglés, pero el costo sube a 4 tokens.
La propia OpenAi aclara que como regla general, 1 token equivale a 4 caracteres en inglés y 100 tokens a unas 75 palabras, pero advierte que esta regla no puede trasladarse a otros idiomas.
Una situación ventajosa
Según el estudio, la ventajosa situación del inglés también es reflejo de los conjuntos de datos con los que las empresas entrenan sus inteligencias artificiales.
Los mismos problemas se reproducen con formas diferentes de cuantificar el costo como el conteo de bits o de caracteres y aparentemente, ningún idioma puede superar la practicidad del inglés, que seguiría presentando costos más bajos debido a su mayor compresibilidad en menor número de tokens.
Además, se concluye que el problema no radica en la forma en que se ha monetizado, sino que es una limitación de la tecnología y de los modelos base considerados para el entrenamiento de la IA.

