Estas son las páginas web de las que ChatGPT extrae su información
Modelos de inteligencia artificial generan sus respuestas con base en datos protegidos por leyes de copyright

Una investigación realizada por The Washington Post indica cuáles serían las páginas web que utiliza esta inteligencia artificial para “alimentarse” y generar las respuestas de las consultas realizadas por los usuarios.
Si bien no es posible identificar las páginas web exactas que se utilizan como fuente en el caso de ChatGPT pues solo OpenAI tiene la lista completa, sí es posible identificar de qué conjunto de datos extrae la información, no solo esta, sino la gran mayoría de inteligencias artificiales.
El llamado C4 es el conjunto visitado por ChatGPT y otros modelos similares para generar respuestas a las consultas de internet y está compuesto por alrededor de 15.1 millones de sitios web de diferentes temas y orígenes.
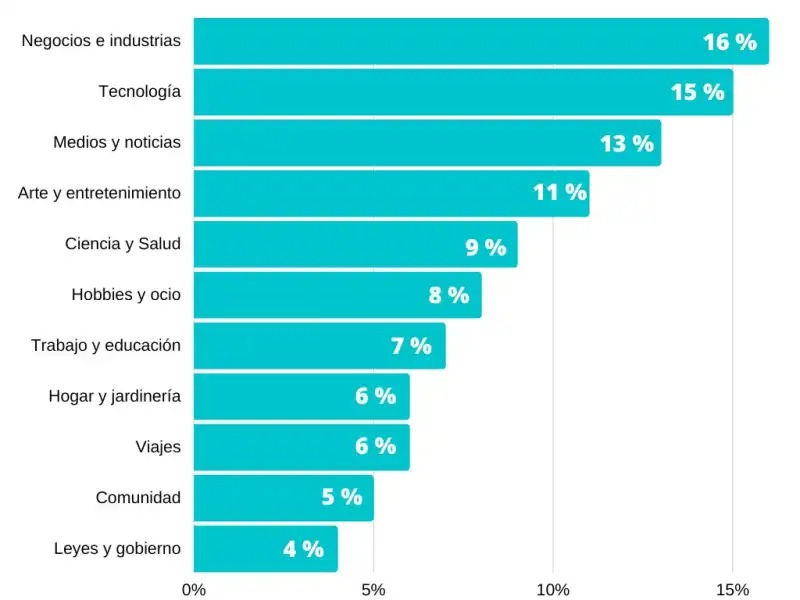
La investigación realizada indica que en este conjunto de datos se encuentran sitios web relacionados con los negocios, tecnología, noticias, arte, ciencia, entre otras especialidades.
Muchos contenidos extraídos de estos sitios están protegidos por derechos de autor, por lo que cada chatbot que utilice el conjunto C4 como fuente, podría estar infringiendo esta normativa en el proceso, ya sea para una consulta eventual o en caso de que un estudiante pida que la inteligencia artificial haga su tarea.
Según el Instituto Allen para la Inteligencia Artificial, que también participó en la investigación, el símbolo de copyright “©” aparece más de 200 millones de veces en el conjunto de datos C4.
Algunas de las páginas web de las que se extraen datos son Fool.com, Kickstarter.com, Patreon.com en lo que respecta a contenido relacionado con negocios, aunque muchos de ellos estén protegidos por derechos de autor.
Sin embargo, estos no son los sitios web más utilizados en el cómputo global. Esta categoría la comprenden páginas como patents.google.com que recoge patentes emitidas en todo el mundo; wikipedia.org, la conocida enciclopedia online que puede ser editada por los usuarios; además de scribd.com, una biblioteca digital por suscripción.

El contenido buscado por las inteligencias artificiales también comprende algunos medios de comunicación y sitios web de recopilación de información; pero aunque muchos de ellos puedan ser fuentes fiables de producción de contenido que es útil para los usuarios, esto no implica que no se hayan incluido fuentes que aportan datos falsos, sesgados y en muchos casos incompleto.
Estos sitios web “informativos” incluyen aquellos que difunden teorías conspirativas o información falsa, además de datos que aportan pensamientos radicales que pueden ser dañinos para los usuarios, en caso de que esta información sea presentada a modo de respuesta a una consulta.
Una muestra del sesgo informativo es que, según el estudio, se detectó que de los 20 sitios web religiosos de los que se extraen datos, 14 de ellos eran cristianos, dos eran judíos y solo uno era de tendencia musulmana.

